输出是否满足明确格式和约束
有些任务需要 JSON、固定字段、必备词或禁用表达。输出像样还不够,先要能被下游接住。
v0.2 direct baseline · 12 task run
一个把 AI 输出放进可重复流程里检查的静态评测样本。它关注任务交付是否稳定、清楚、可复查,而不是一次回答看起来是否漂亮。
当前已跑通一轮 12 道真实风格题目,覆盖信息抽取、改写和制度问答。页面展示的是这轮样本在基础规则口径下的结果,以及这些结果适合怎样阅读。
Why
有些任务需要 JSON、固定字段、必备词或禁用表达。输出像样还不够,先要能被下游接住。
同一批题、同一套记录、同一套检查口径,才方便讨论这条流程是否稳定。
失败样本需要留下可追溯记录,后续才能判断是格式问题、约束遗漏,还是需要更强的人工判断。
很多办公任务不会完全交给模型。清楚、结构化、可核对的输出更适合进入人工复核流程。
Task Set
题目覆盖抽取、改写、问答三类任务。这里展示的是浏览版摘要,重点保留场景、输入材料、关键约束和期望输出形式。
Method
当前公开跑通的是 direct 基线:拿到题目后直接生成答案,再进入统一记录与检查流程。
信息抽取看材料要点能否整理出来;改写看给定素材能否按约束重写;问答看制度或 FAQ 能否转成可用答案。
先看输出是否满足最基本的格式与约束要求,包括输出类型、必备字段、禁用表达和 JSON 可解析性。
用几项简单指标快速扫一眼输出覆盖情况,例如非空输出、必备词覆盖、引用信号和结构有效性。
把未通过样本按现有规则做初步归类,方便后续复盘。当前这轮没有触发规则失败样本。
Run Result
在当前这组 12 题和当前规则口径下,基础规则检查整体通过。这说明 direct 流程在这轮样本上,基本能稳定给出可解析、结构合规的输出;它不直接覆盖更深入的事实正确性与业务质量判断。
结构、字段、必备要求和禁用表达在本轮没有触发失败。
抽取、改写、问答三类题目数量均衡。
本轮主要价值在确认基础流程闭环,而不是拉开模型或题型差距。
这些图大多接近满格,说明本轮样本在规则层没有形成明显高低差。它们更适合用来确认执行链路、题型覆盖和检查项状态,而不适合作为质量排名。
如果后续加入更多样本、人工评分或多工作流对照,图表才会承担更强的区分功能。
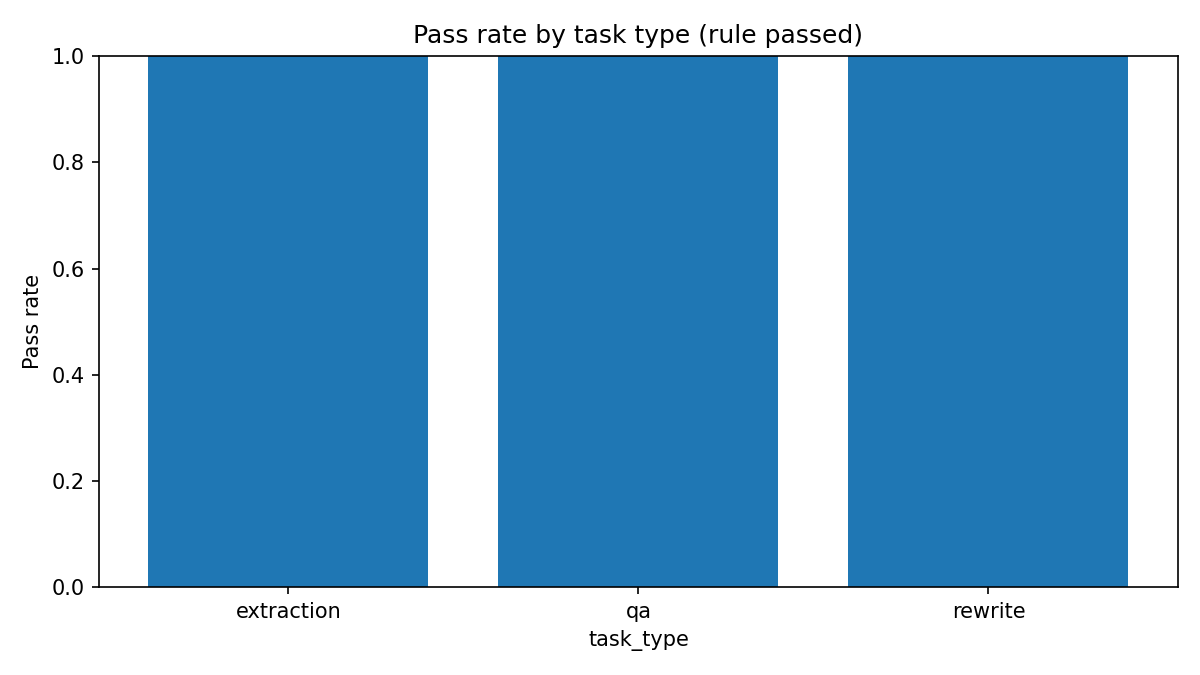
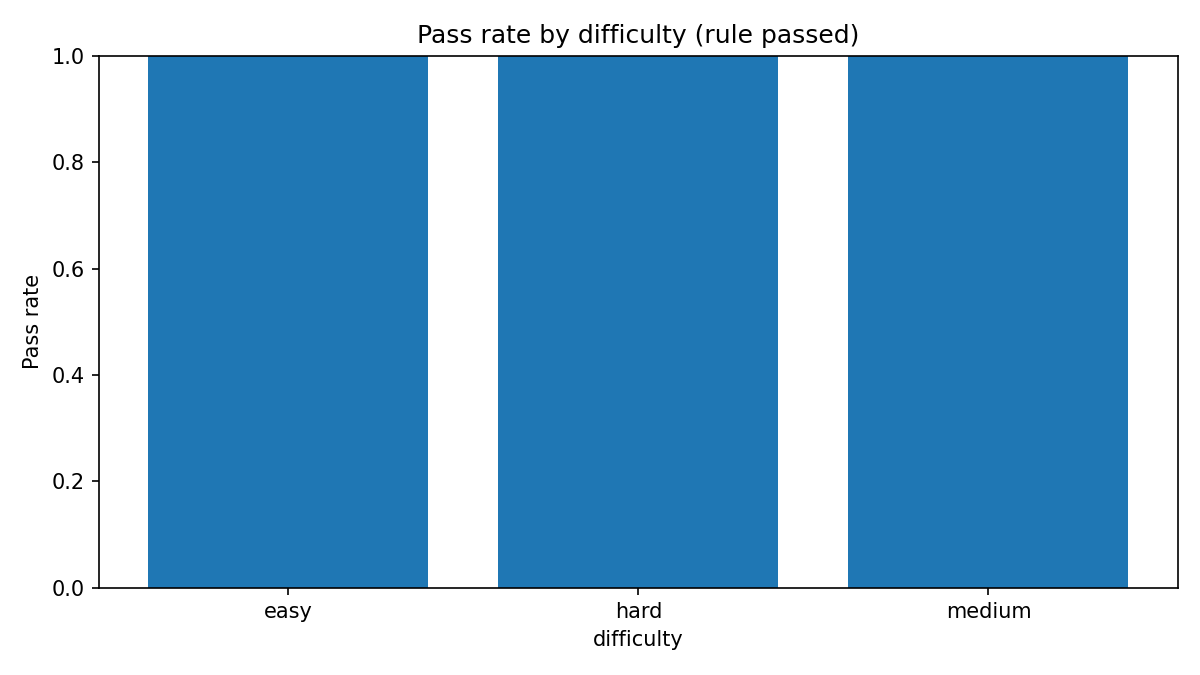
每个检查项在本轮均为通过状态。它能确认输出形式与显性约束,没有确认事实是否完整正确。
| 检查项 | 通过 | 未通过 |
|---|
代理指标只用于快速扫视输出状态,不是综合质量分,也不替代人工核对。
| 指标 | 值 |
|---|
正在加载本轮汇总数据...
Interpretation
这类评测适合先放在规则清晰、格式固定、后果可控的任务上试跑。它能帮助判断哪些环节已经适合进入半自动流程,哪些环节还需要检索、人工复核或更严格的语义评审。
对合规、数字口径、对外承诺和人事财务类任务,即使基础检查全绿,也应该保留人工把关。本项目更接近工作流决策:看一套做法能不能反复交卷,以及下一步该补哪种检查。
Status
当前完整跑批以 direct baseline 为主,retrieve、planexec、humangate 仍是架构预留位置。
样本量仍小,本轮结果不能外推到所有业务场景。
quality proxy 仍是粗粒度信号,更深入的事实正确性需要人工或更严评测协议。
下一步会围绕多工作流对照、人工评审和更细的失败归因继续补齐。